02/02/2026 10:20 AM
02/02/2026 10:20 AM
I trained a DORA yesterday on the ClearVQA ground truth cqs. It does outperform in val loss, but also just looking at the output qualitatively, they are better questions. Like substantially better and more specific. It is annoying because it takes much longer to train, but maybe it is good to use. Could also try a run with a normal LoRA with a larger rank. But I think it is more important right now to get to the next step.
I am writing a streamlit app that will allow me to interact with the
Wei interview
Previous projects:
Leia stirling project. Hard to define clear goal.
How did you figure out what research to do?
Inspiriation from 204. Motivated by Astro. Navigation using open language command. Noticed that ambiguous commands (calling them implicit commands).
Used foundation models. Which?
How was the scene graph represented? Cosine similarity to what? What would need to change to pass the embeddings in directly.
Couldn't put whole scene graph into LLM.
Met him at the potluck.
Wants to work in embodied intelligence. Ask if he wants to do closed loop clarification.
Use multiple different models to verify each other.
What is your experience with language models?
What is your experience with VLAs?
What projects do you want to highlight for me?
What software engineering experience do you have?
Have you used HuggingFace Transformers before?
Used openAI api for LLM. Used gpt 4o mini. Used low temperature.
Say I want the model to output in a specific format, say JSON. Do you have an idea of how to do that? Practically with libraries or theoretically would suffice.
If I have to load a large model with limited RAM, what techniques would I use to do that?
Have you used simulation environments before?
Mostly Gazebo. Trying with Isaccsim. Used Isaccsim for generating occupancy grid. Used pybullet for courses.
Say I give you the pth/safetensors file for a model that can clarify,
Why do you want to work with us? What experience do you wish to gain?
Talk about Jason.
Anything you want to ask me?
- [ ] @TODO Ask jason if undergrads will come to lab meetings.
Machine learning training:
Rob320 did theoretical background in optimization problems.
Wants to go to grad school. SUGS for 1 year and then PhD in robotics. Worked at Carnegie melon for schema learning. NLP. Predict the supply chain disruption in industry. Did data collection and cleaning.
Representation of knowledge is a core idea. Semantic mapping and navigation and embodiment. Better understand the world and environment.
- [ ] @TODO Has done SURE before. Criteria on website saying SURE is for exploring research.
Notes I should have written before:
Data leaks:
The model gets way too good at predicting the exact ground truth clarifying question for some images. I initially thought this was an actual data leak, but now I think it is more subtle than that. The phrase "Are you asking about the health benefits of the fruits shown in the image" appears exactly in the training set. So my hypothesis is that using a single LLM to generate ambiguous questions will lead to massive correlation between questions relating to similar images which means you get information leaking from train to val even if individual samples don't leak. This is very bad since if you can learn to predict what the ambiguity that got introduced is, you can predict the final answer without needing to actually ask the clarifying question. It makes having a val set from an entirely different dataset vital.
I was thinking that one could use a language embedding model to check for clusters of questions and ensure that everything in the val set is significantly different than everything in the train set.

Uncertain ambiguity:
Situations like this will make it very difficult to predict the additional error as even I as a human cannot tell if this question is ambiguous. The boy on the left is holding a hotdog, potato chips, and soda. If a human was asking this question, that is what they would expect in response. We want questions that a human would ask where the answer is truly something a human would not expect. This dataset doesn't really meet that burden. That being said, there are also questions that are truly ambiguous in a way that a human would do so it is not all bad.


This also makes me think that there are easy ways to reward hack for a policy generating ambiguous questions as they can just write questions that are mostly unrelated to the actual answer and then rely on the clarification model to uncover the true question.
Insistence
After cold start on the cq dataset the model always asks the same question no matter what the follow up is. Perhaps there needs to be an objective during RL to pursuade it to ask diverse questions?
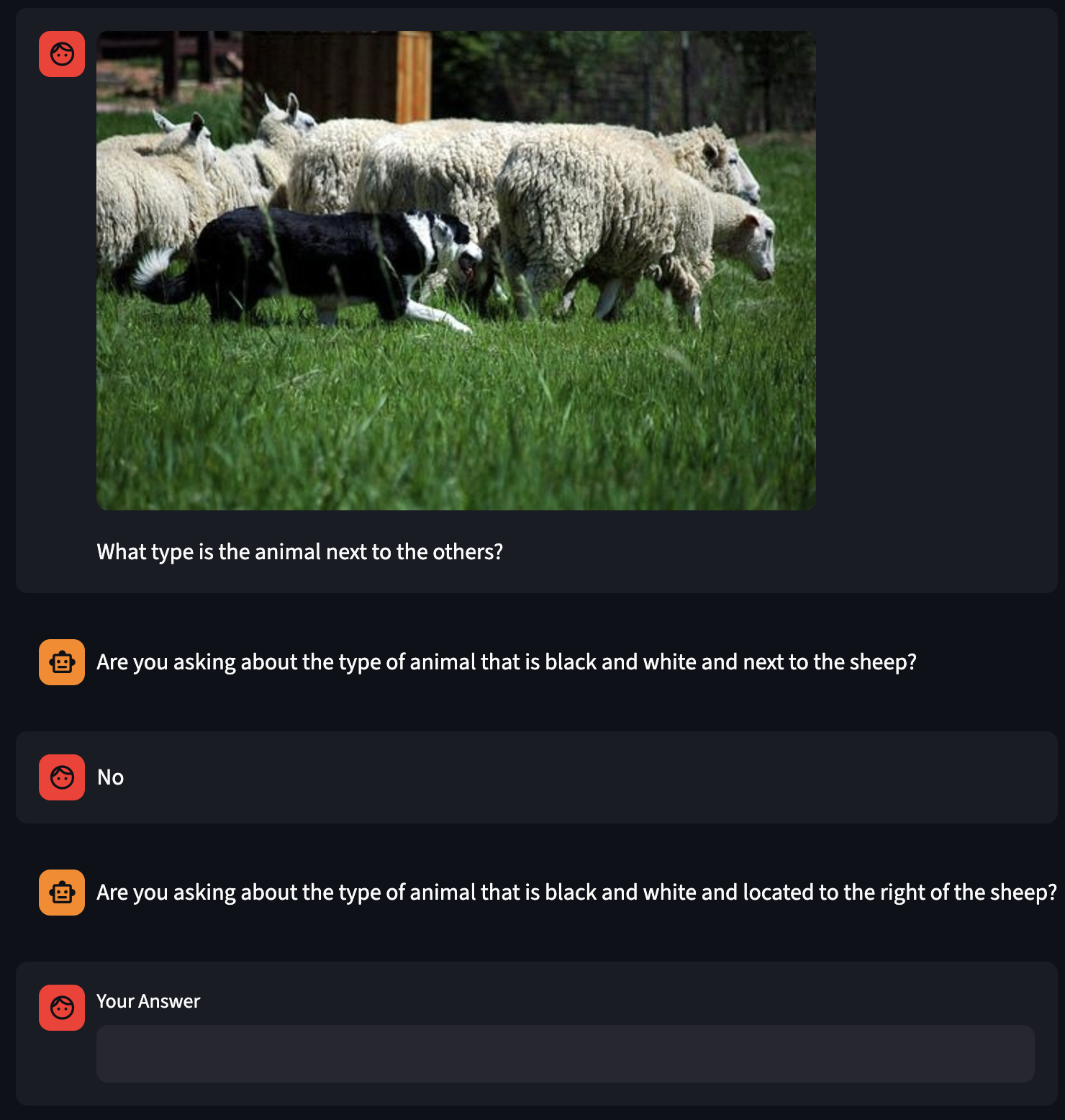
LLM Training
Ensure that you are using the correct labels when you pass data into the HFTransformers thing that converts chat format into the LLM tokens. If you have a message with a chatter label (like "agent") that is not actually a chatter the model knows about, then it will just ignore that message.
Vision-Language model training
Different models handle the image tokens differently which can be annoying. Especially when batching input. My solution was just to resize and pad everything to a square with known dimensions. Then it is easy to stack them.