04/02/2026 5:33 PM - SNU Meeting Prep
04/02/2026 5:33 PM - SNU Meeting Prep
Presentation
Section 1: Recap
Better example of a model making an assumption in the wild.
Dataset classification with expanded datasets.
What tasks are we trying to do and how are we trying to achieve them?
Example of assumption

Section 2: Updates
I have been working on the cold start SFT and prompting that has to be done before the RL we can achieve valid multi-turn clarification dialogs that can be used for training.
What we need:
A model that can ask valid clarifying questions about an image. Internally I call this the clarification question model or CQ model.
A model that can answer the clarifying questions correctly. I call this the Answer model.
A model that can take the entire dialog and predict the answer to the unambiguous question. I call this the Inference model.
Put checkmarks next to the ones that are done
For each, we need to have the ability to generate a diverse set of outputs for the RL to work.
Current work
I have been working on getting the framework together while collecting insights on ambiguity datasets, getting a better grasp on how to fine tune VLMs, and understanding how I can best set up rewards to get the model to ask good questions in a multi-step dialog.
Example:
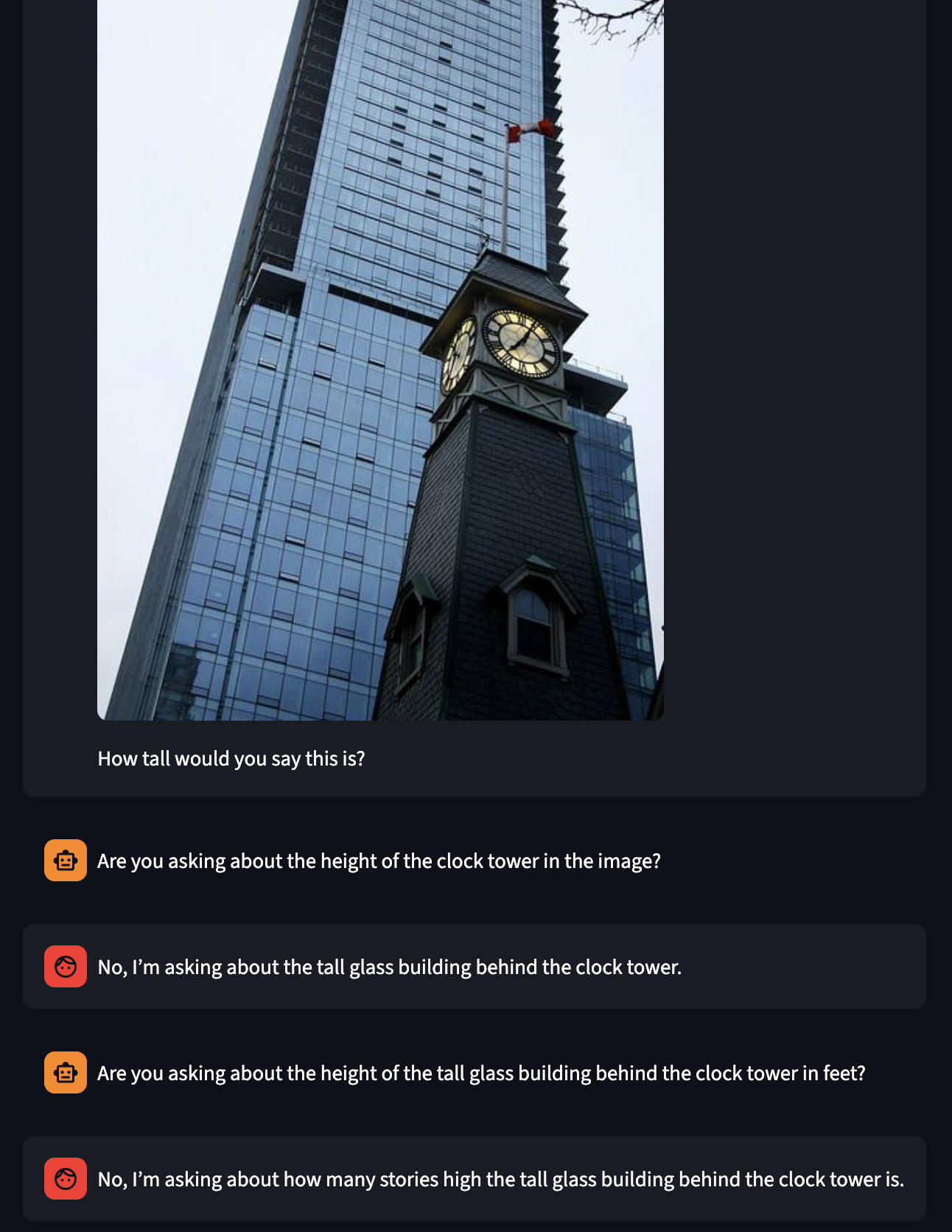
Note that these are 32b models. The CQ model is fine-tuned on ClearVQA while the answer model is just prompted.
SFT:

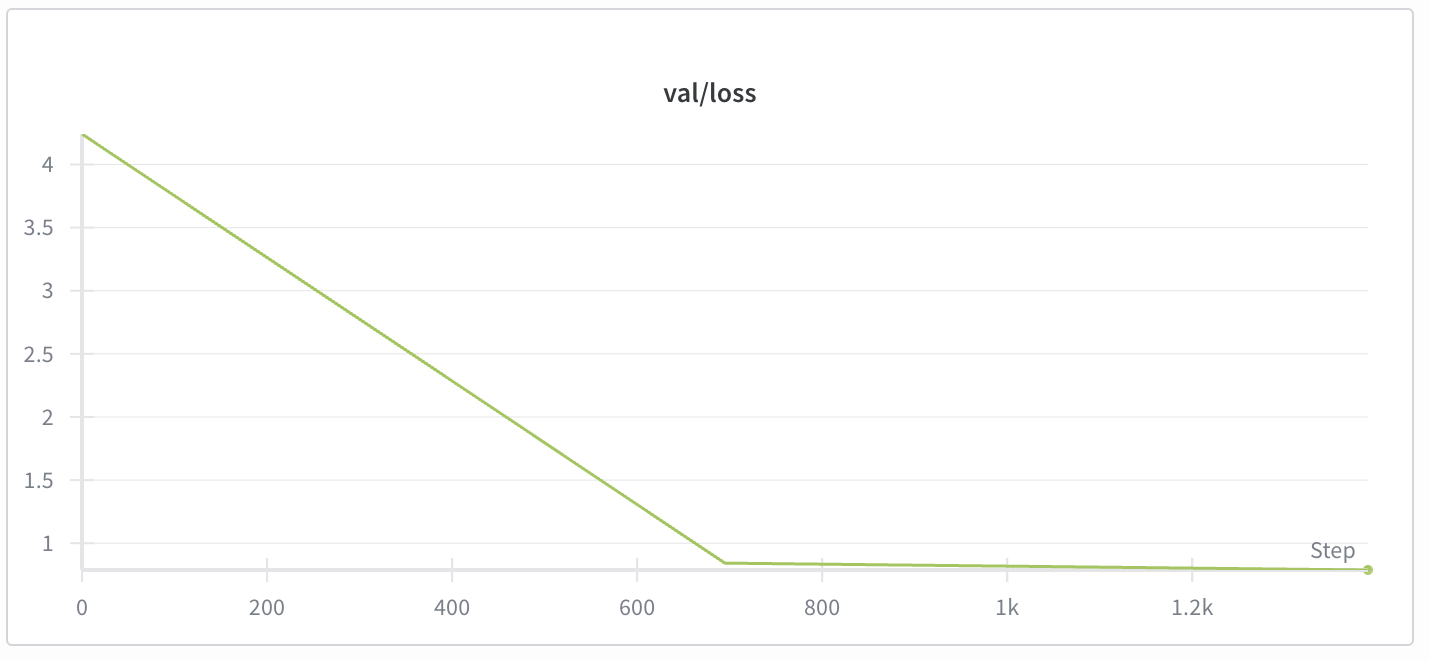
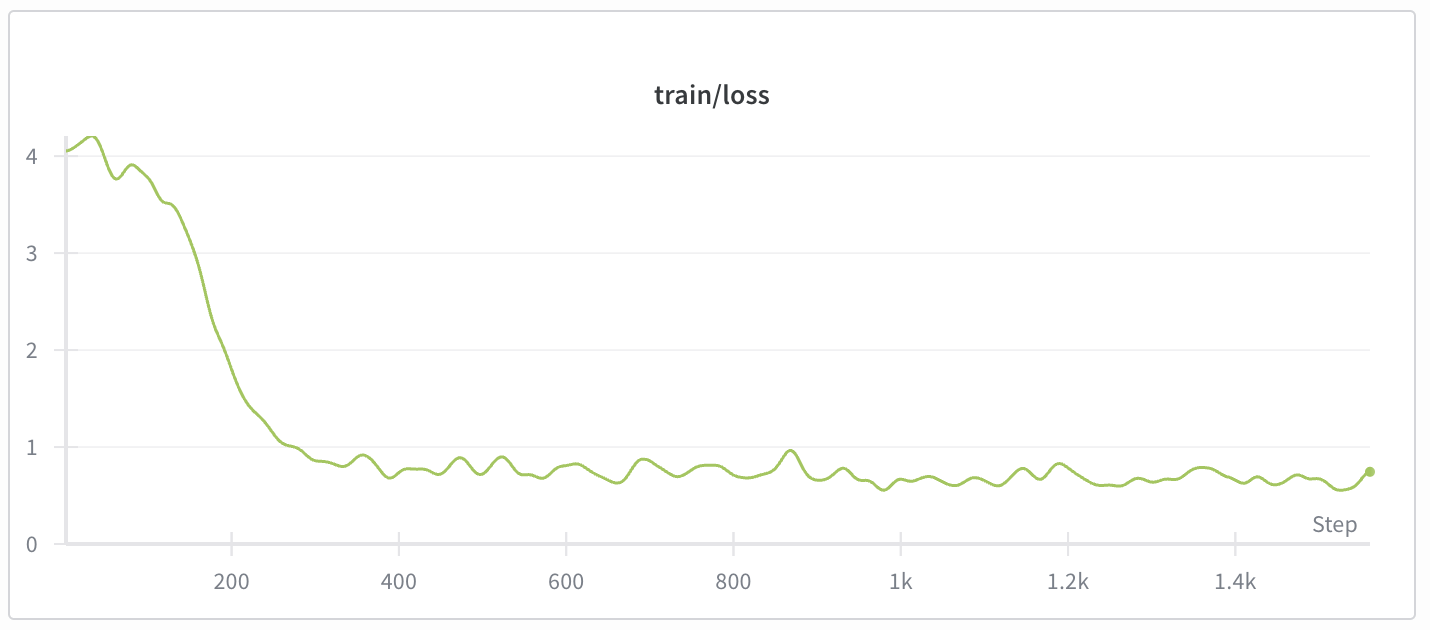
Converges quite fast. To be expected since this is a simple structural change to the output. We are not adding any new abilities, just directing existing ones. This is using a LoRA, but I also have prompt tuning being evaluated.
Sample Diversity:
For RL, we need diversity on the outputs of the CQ model and the Answer model. The simplest method to achieve this is random seeding with non-zero temperature, but another more advanced method is group beam search where multiple beam searches are run and we get all of them. Group beam search performed very poorly, massively degrading the quality of the output. I believe that I am using it incorrectly or have misunderstood how to set it up, but I tried many hyperparameter combinations and could not get good output. However, defaulting to simple random sampling was effective. Diversity is not forced in this case which does mean post-processing is needed.
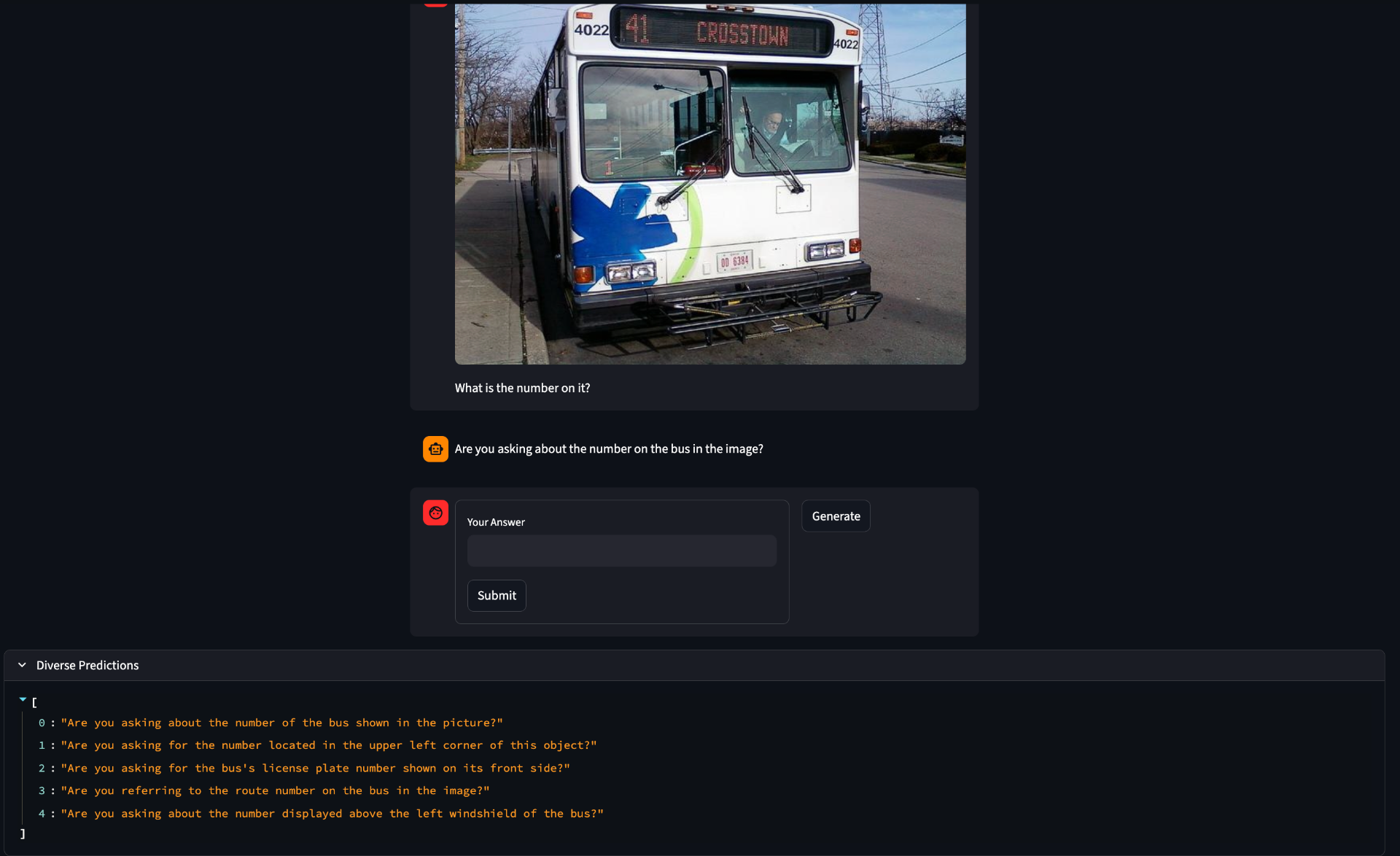
Note that the answer model generally has a single consitent answer when taking many samples wheras the CQ model has a lot of internal diversity. I have not quanitified this, but it aligns with the intuition that there are many possible ambiguous aspects to be constrained, but each constraint only has a single value.
Challenges
Data Leaks:
While using the ClearVQA dataset for SFT on the clarification question model, I noticed that the predicted clarifying questions were suspiciously similar to the ground truth.

I thought I had a data leak, but it turns out that there are just very similar questions in the training set. Almost exactly the same wording, just substituting a couple words. Therefore, the val set is not very useful for checking whether we have actual "understanding" of the ambiguity or if we are simply matching types of ambiguous questions to types of clarifying questions.
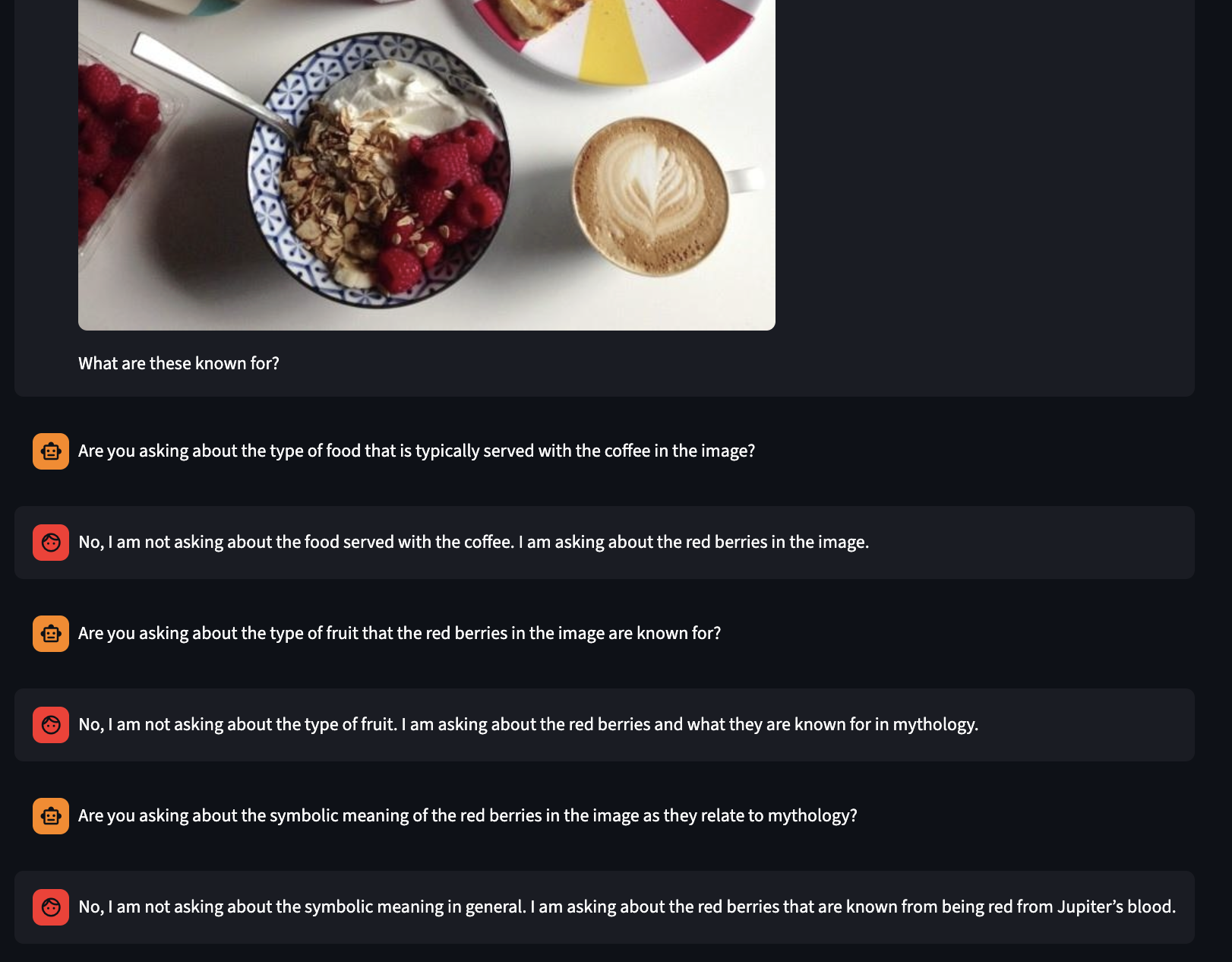
Uncertain Ambiguity:


This is a good example of what I mean when I say that it is important to match the distribution of ambiguous questions to real human distributions. In both of these cases, I would argue that it is impossible to know if there is ambiguity. A human would likely answer immediately without asking a follow up because a human would make a reasonable assumption that we are not talking about something as hyper-specific as what is given as the gold answers here. I would answer, pizza for the first one and chips and soda for the second. I think this is really just a failure of the paradigm though.
Insistence
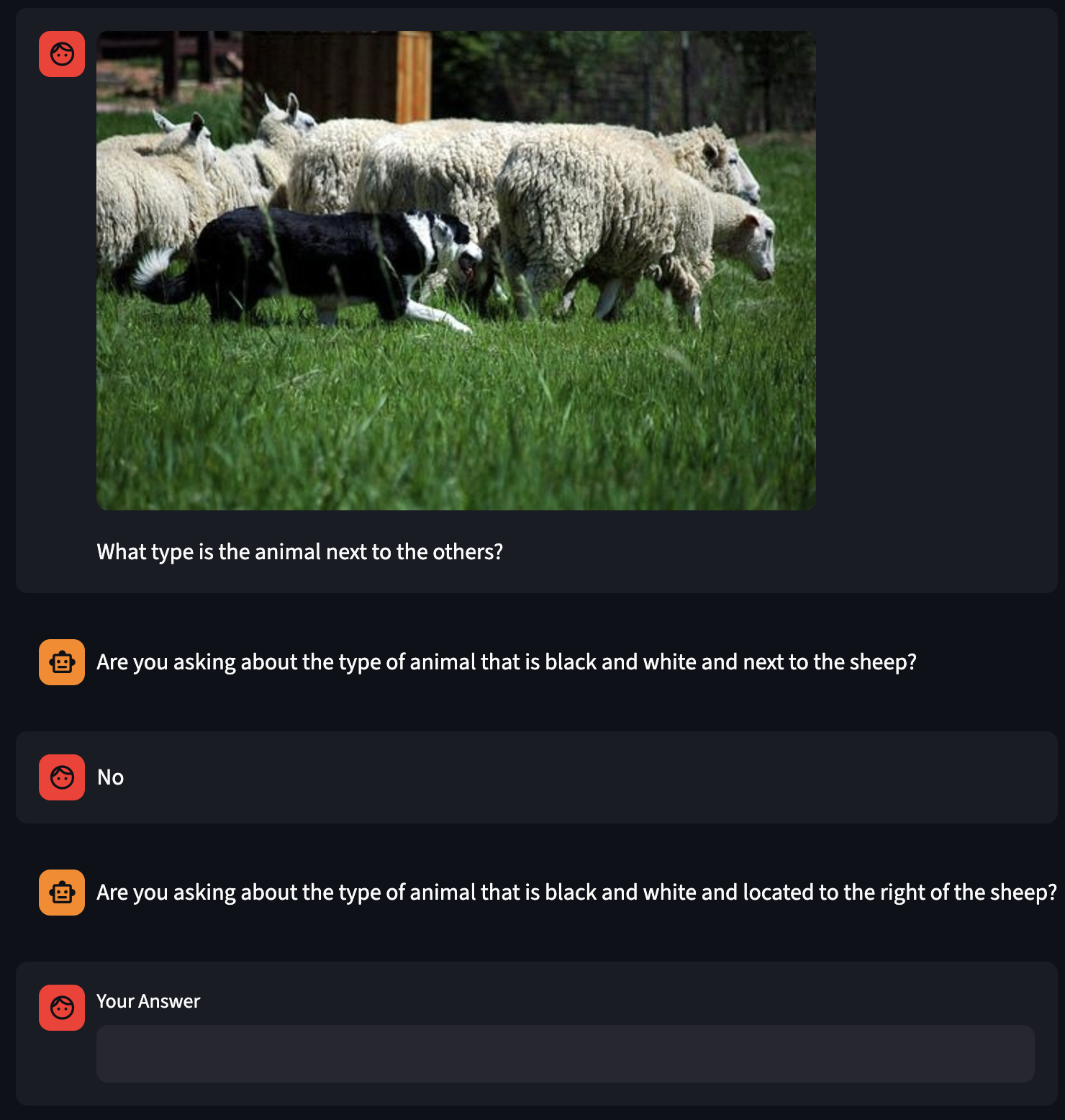
After cold start where we use SFT to train a VLM to ask a clarifying question.
My hope is that by using sampling techinques to promote diversity in the clarifying questions, we can get enough internal diversity that the RL step can act on to train the model that asking the same question repeatedly will not be useful for gaining information.
I have not seen solutions to this in previous works.
Do we need a specific part of the reward function to prevent repeated questions? Or does the objective of minimizing additional error lead to low reward for additional questions since it adds no information and so the difference between the current node error and final node error will be zero?
Answer Leaks:
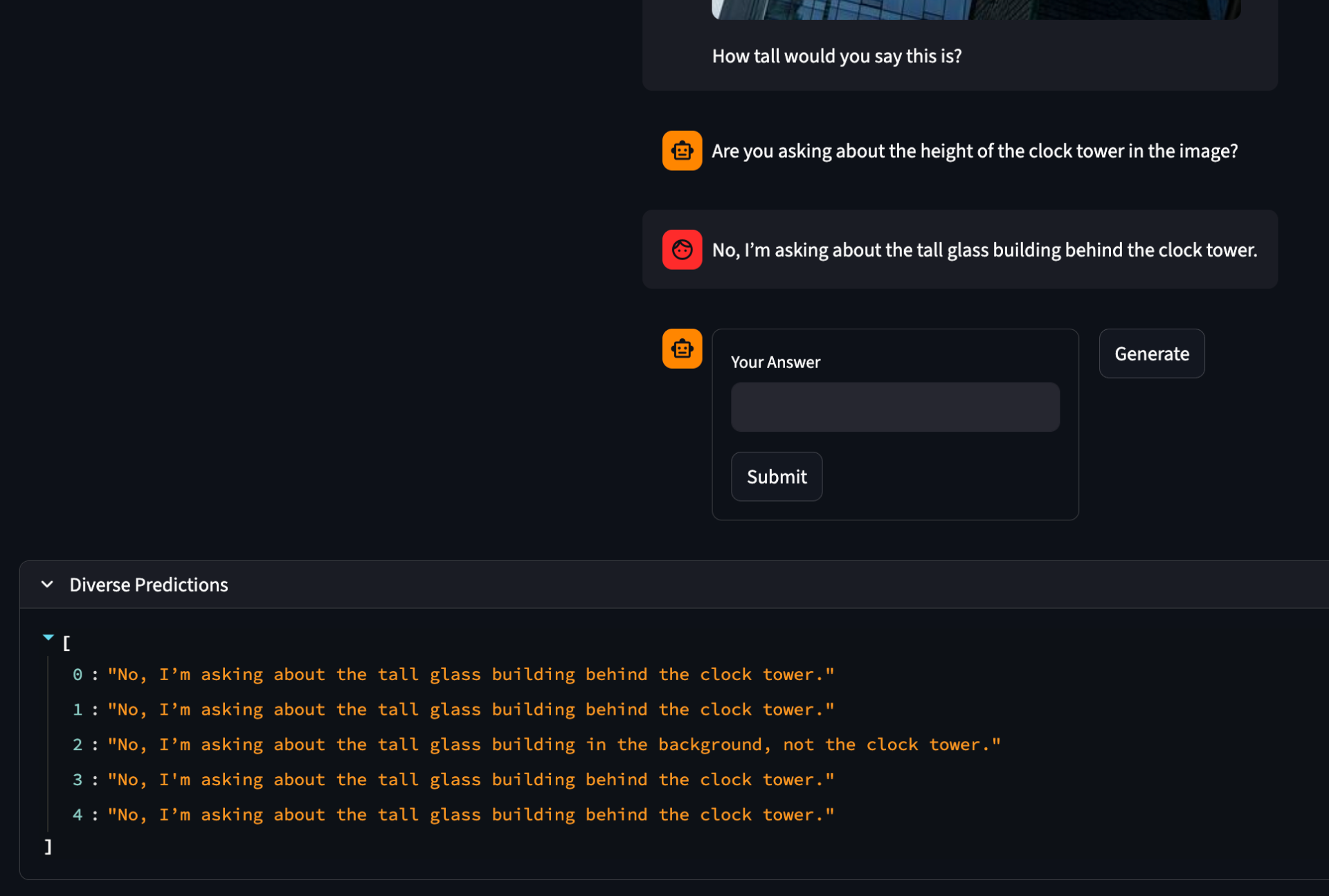
The Answer model tends to give away the answer even after a lot of experimenting with prompts trying to ensure it does not leak the answer. There is no training data available so I am unable to train a LoRA to ensure the model behaves as expected. This may become a problem later during RL if the CQ model is able to exploit this tendancy to force the Answer model to give it the answer. However, this may not happen so, while it is good to be cautious about it, I will continue under the assumption that the CQ will learn anyways.
If we look at the diverse predictions for this final outout, we can see that in some cases it keeps it vauge in in other cases it leaks the answer. If this is the rule, then it may be that the correct setup for the RL is a minimax style game where for the Answer model we always look at the branch that led to the highest depth before finding the correct answer. In effect, choosing the path where the model is a hazy oracle as opposed to a good oracle.

Section 3: Open Questions
How do we deal with the tendancy for the answer model to give away the answer?
How do we bridge the "llm-to-real gap" when datasets that have real human data are so small?
Is it at all valid to evaluate on a benchmark like ClearVQA (or other LLM generated datasets) when it is becoming clear that they have such correlation between questions that it might as well be a data leak?
How can comparisons between methods using LLMs as question answers be fair when the LLM can simply leak the answer? Exclusively human validation where a real human interacts with the clarification model?
How can we overcome the problem with LLM generated datasets have large correlation between generated types of ambiguity, leading to effective data leaks from train to val and test? Using a grouping strategy that ensures that all questions with high similarity fall into a single split?