Acknowledging Focus Ambiguity in Visual Questions
⬅️ [AQUA: Toward Strategic Response Generation for Ambiguous Visual Questions](<./AQUA_ Toward Strategic Response Generation for Ambiguous Visual Questions.md>) | ⬆️ [Reading List](<./README.md>) | [A Survey on LLM-as-a-Judge](<./A Survey on LLM-as-a-Judge.md>) ➡️
Acknowledging Focus Ambiguity in Visual Questions
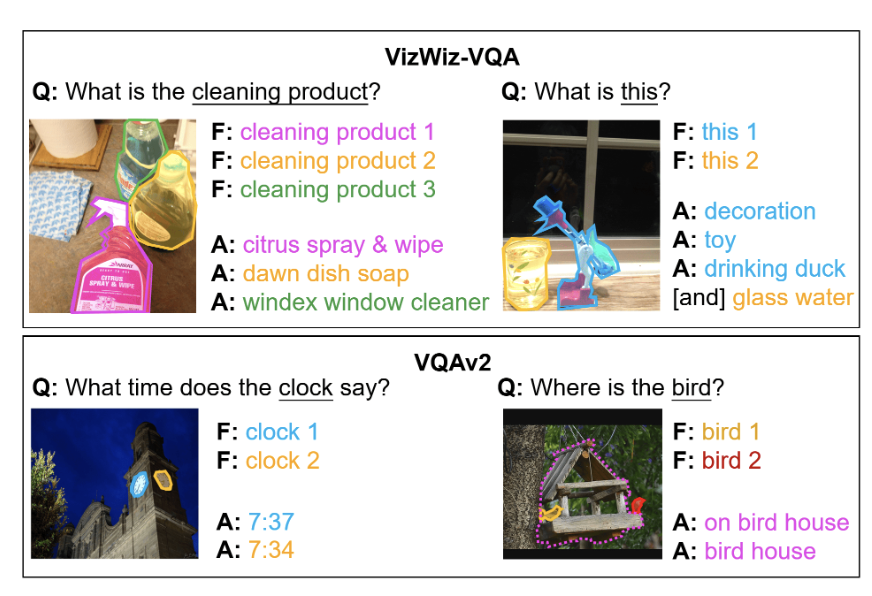
Could be a good candidate for a dataset to use. Still a bit too small, but can be combined with ClearVQA if we wish. Also focuses on referential ambiguity to the exclusion of other types.
https://arxiv.org/pdf/2501.02201
Focuses specifically on referential ambiguity where the question could refer to multiple objects.
For PACO: Used AI suggested questions. Annotator could choose to enter their own.
5500 questions that were from human datasets and then were labelled as ambiguous.
Introduced me to https://arxiv.org/html/2508.09809v1 which contains diagnosis datasets for mental health conditions.
⬅️ [AQUA: Toward Strategic Response Generation for Ambiguous Visual Questions](<./AQUA_ Toward Strategic Response Generation for Ambiguous Visual Questions.md>) | ⬆️ [Reading List](<./README.md>) | [A Survey on LLM-as-a-Judge](<./A Survey on LLM-as-a-Judge.md>) ➡️