09/03/2026 12:51 PM
09/03/2026 12:51 PM
TODO
- [x] RGSC Survey Stuff
- [x] Print out posters
- [x] Get candy from grace and set it up in kitchenette and atrium
- [x] Set up posters in atrium, grad lounge, kitchenette
- [x] Email professors to get survey slide in lectures for large ROB classes
- [ ] Update paper
- [ ] Prepare outline
- [ ] Draft methods
- [ ] Research
- [ ] Create metrics that apply to the folder of trees
- [ ] Work further on getting the RL working. Hopefully get the logprobs saving correctly.
Update Paper Outline
Intro:
Where ambiguity becomes a problem.
Mention BullshitBench as an example.
Related tasks like rewriting an ambiguous question to be specific.
Prior Work
All the benchmarks that produced papers. ClearVQA and the such.
TPO
Oh just realized that I can't call the method Tree Relative Policy Optimization because TRPO is already taken lol.
TreeRPO, TRPO, and DTPO are recent similar methods.
These only sometimes focus on LLMs and when they do it is on the task of chain of thought. The extension to the task of also deciding when to stop adds another layer to the method and we also do normalization differently.
Extending beyond binary rewards at the endpoint and integrating intermediate reward shaping which cannot be done if we assume reward is bernoulli.
Cite that bayesian LLM paper my dad sent as well. That is effectively what we are doing, but with RL instead of immitation learning.
Datasets:
Ambiguous VQA Datasets
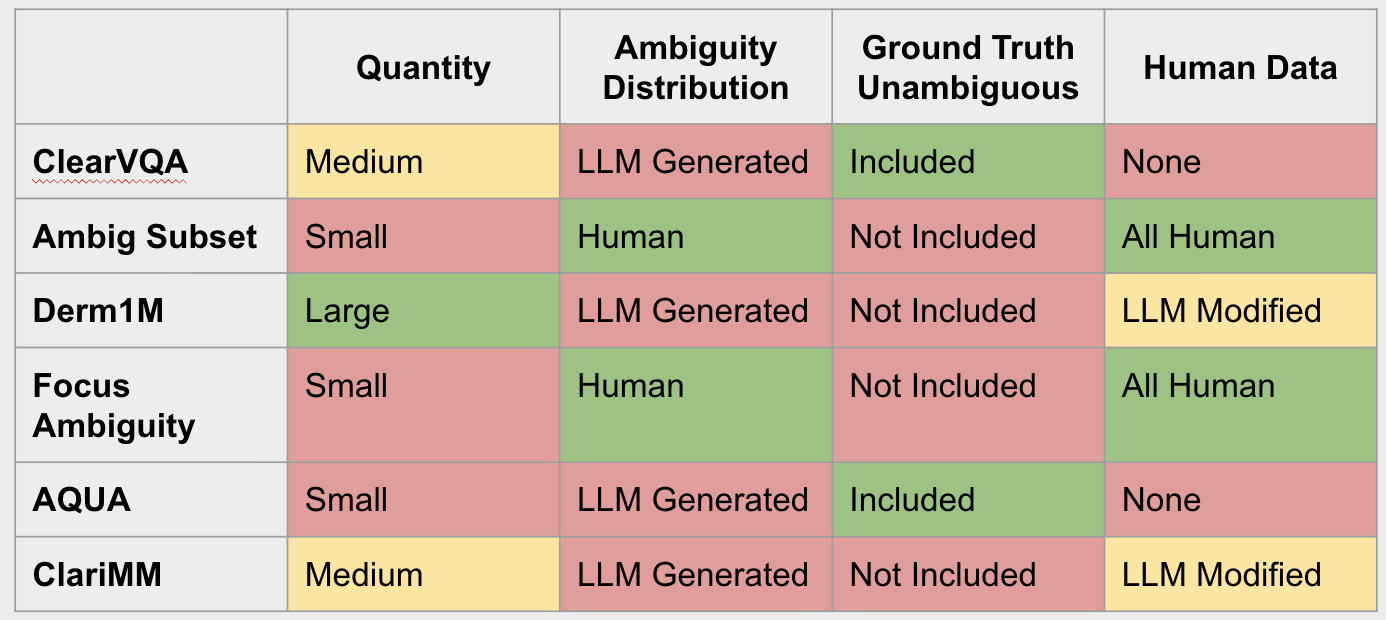
Outline for each that was in the presentation and create the table that was in the presentation.
| Dataset | Quantity | Ambiguity Distribution | Ground Truth Unambiguous | Human Data |
| :--- | :--- | :--- | :--- | :--- |
| ClearVQA | Medium | LLM Generated | Included | None |
| Ambig Subset | Small | Human | Not Included | All Human |
| Derm1M | Large | LLM Generated | Not Included | LLM Modified |
| Focus Ambiguity | Small | Human | Not Included | All Human |
| AQUA | Small | LLM Generated | Included | None |
| ClariMM | Medium | LLM Generated | Not Included | LLM Modified |
ClearVQA
Interesting future datasets
BullshitBench testing to see if the models can tell that they cannot answer the question with any certainty.
Derm1M for a task that has real ambiguity. I saw people specifically noting that LLMs are useless for diagnosis because they cannot ask repeated questions well.
We also have CoverageQA which has multiple different correct answers which could be useful to see if our LLM can navigate to each possible outcome.
Methods:
SFT for Cold Start
In order to RL to do its work, it first needs to be able to take near-correct actions. For example, if the model never asks a question in the first place, giving it a reward for asking a question will never result in the model learning to ask questions. RL can only make small changes to the distribution.
Insistence, question presence, and length
Used for reward shaping in order to make the model give answers in the correct format.
There are not datasets of multi-turn question dialogs so when we did SFT it was for a single question dialog.
Presented with image and ambiguous question, ask clarifying question.
This leads the model to always ask a single question, but then after that often revert to just attempting to infer. We want a generalized framework that allows us to apply costs for doing things wrong, like not presenting a question.
We also have a cost for "insistence" which measures the max probability that a prior question in the tree entails the current question. This trains the model to increase the diversity of questions so that even if the model is already confident in the answer it will still generate a diverse output.
Length is a reward that cannot be binary which is important for differentiation from TreeRPO which assumes that rewards are binary and therefore expectations of rewards are drawn from a bernoulli distribution.
Policy Gradient Methods Math
Jason wanted to see math in my presentation that I did not provide. I want to start from the Bellman equation and give a condensed version of the math that leads us to policy gradient.
Baselines for Variance Reduction
We should have the proof here that subtracting off a baseline decreases the variance in the gradient while having no effect on the maximum likelyhood solution for the optimal policy.
DPO
Weighted DPO is one avenue for the RL algorithm. We should have the math. It has largely been superceded by GRPO recently as they make many of the same assumptions. Speaking of which here we should talk about the ability to roll out multiple paths from the same starting state as a requirement for the next set of algorithms.
GRPO
Note the main change of the baseline, but also talk about the normalization. Normalization is the main difference from TreePRO (besides of course the fact that we also need to learn a stopping policy) so I think it is necessary to outline.
TreeRPO assumes that all rewards are sampled from a bernoulli distribution. To integrate reward shaping in the most natural way, it is useful to be able to apply arbitrary costs as subtractions from the value. Now, we could also implement this as multiplications by factors in (0, 1), basically saying "Having an answer of this length makes the probability of ending here and saying the model got it wrong p%". If my normalization technique doesn't work well, I can try that out and use the bernoulli normalization like they do in the TreeRPO paper.
Tree Extension
Three model game
We have our policy, the question model, our agent, currently a LLM with a single prompt, and our inference model, the same model as the agent, but prompted differently. These three form a game that is highly generalizable for two agent interactions that have a scorable outcome.
Infer/Defer and Optimal Stopping
Integrating a decision to stop into multi-turn dialog.
Constant depth of 1?
Jointly train a model to predict the probability of error if we infer? Even then, what threshold do we use? Threshold changes the game and so changes the policy we will learn.
Right now we opt for an optimal stopping during training where we use the fact that we know the future direction the consersation will take to always make the perfect infer/defer decision. (Highlight the bellman equation with optimal stopping)
Note that though we are using this to learn when to stop in a dialog, it is also applicable to chain of thought.
LLM-as-a-Judge
Take the insights from section 3 and then put the actual prompts down in the appendix.
Output Clustering
We use biconditional entailment to cluster model outputs to reduce computational load. We generate N samples then compute the entailment (using bert something) between each pair. We take the biconditional entailment to be $min{S, S^T}$ element wise (saying two statements are the same if both mean each other. If only one means the other then that's fine.) and then using agglomerative clustering.
Distributional RL for stopping criterion
We note that the stopping criterion used by Stephan is very similar to the value function in RL. However, it needs the full distribution of probability of error. Which I have learned is what is given in a field called Distributional RL where instead of just learning the value function, we learn to predict the probability distribution of future error.
Doing it this way would allow us to integrate a stopping criterion into the training of the policy, but at this point I don't know how exactly we would want this done. We could directly implement Stephan's work which I believe outputs a probability of inferring which could then easily be integrated into the current paradigm as a function that is used in the bellman equation as an action selector to make the final equation
But then we also have a hyperparameter which controls how sensitive we are to error. And perhaps we are more sensitive or less sensitive in different circumstances or with different agents.
VLLM insights
Put in the options you need to get the token ids.
Talk about how I ran into freezing issues that I couldn't solve. Shifting to use their built in server and the openai interface ended up working.
Results
Need to make the script that makes the graphs.
Roadblocks and other notes
It appears that for the most part "ambiguous" questions from these datasets have very little real ambiguity. Almost everything can be answered in a single step of clarifying questions.
Desired error should realistically be an input to the network because the optimal strategy depends on it.
Answer leaks minimax: We may want to make the game slightly harder by using a min over the rewards coming from all the answers to prevent things like the answer model leaking the answer.