04/02/2026 9:14 AM
04/02/2026 9:14 AM
The outputs get really uncreative when I train the LORA on the cold start cq data. I'm wondering if I should try prompt tuning and save the LORA for the RL. I should look at more past papers. I don't remember them having much detail on the cold start mechanism.
Need other metrics besides loss for measuing the ability of a model to ask clarifying questions. Again, look closer at past papers. I felt like most of them were using things like final accuracy.
04/02/2026 11:48 AM
I'm now thinking about which layers to transform and I know that I'm getting too down in the weeds. That is something to explore later after I have the actual RL working.
I also need to actually do the diverse output generation. I think the way to do that is to hijack the beam search so that it returns all of the beams as those have enforced diversity to a certain extent. Otherwise I can use random sampling with some mechanism to ensure that we get enough diversity.
Before my 1-on-1 today I want to have the diverse generation built and integrated into the demo so that I can generate multiple possible paths and then have the user select which they want to use.
04/02/2026 1:13 PM
Ok one-on-one isn't happening so I'll just have that stuff by tomorrow for the SNU meeting.
04/02/2026 1:31 PM
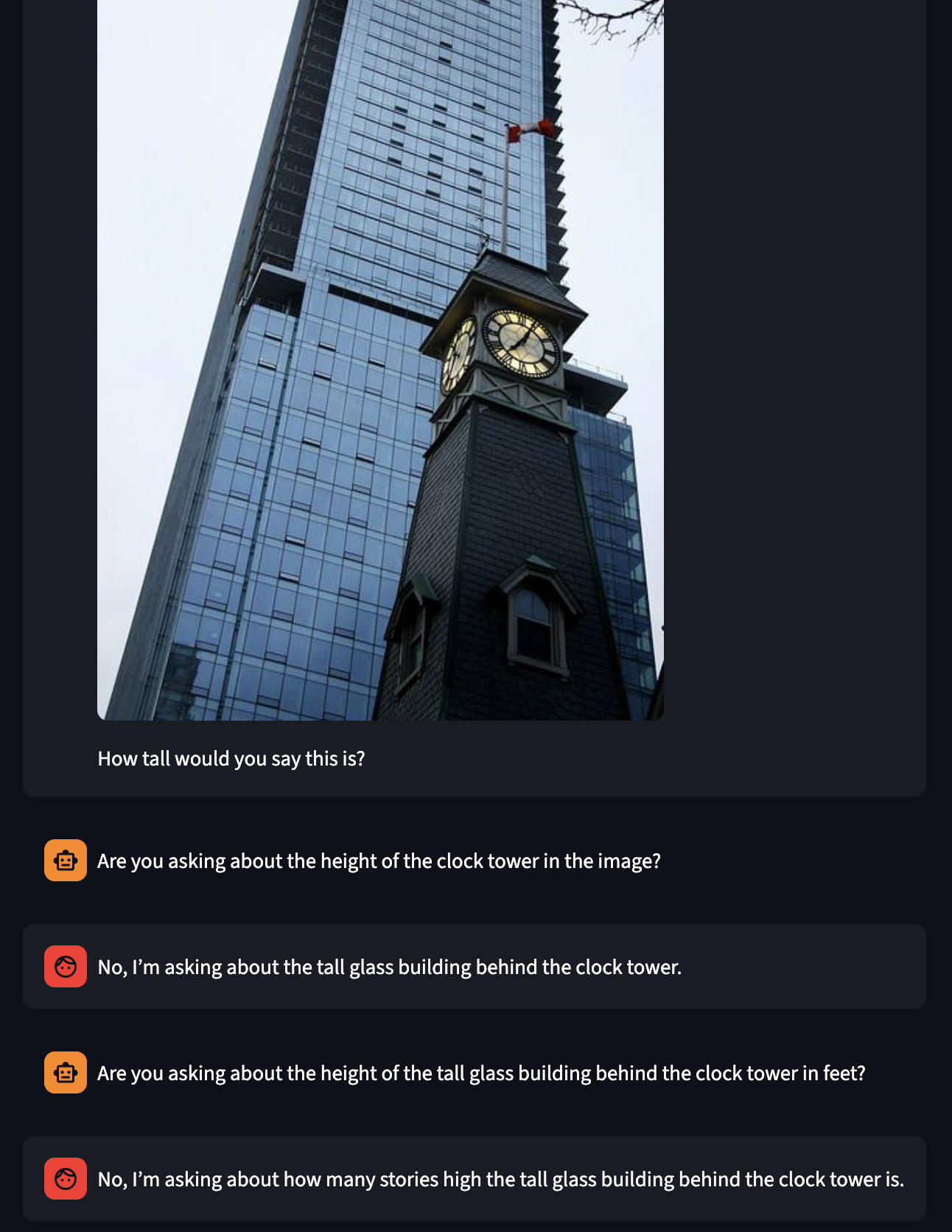
Example of an actual functional multi-step dialog that needed multiple steps to disambiguate the intention. The answer model correctly hid the fact that it was asking about the height in stories and the cq model correctly identified that there was ambiguity in units and clarified it. Good job models.
04/02/2026 3:22 PM
https://arxiv.org/abs/2410.09038
This paper mentions a CovergeQA dataset that uses multiple equally as plausible answers to measure the ability for outputs to be diverse.
04/02/2026 3:36 PM
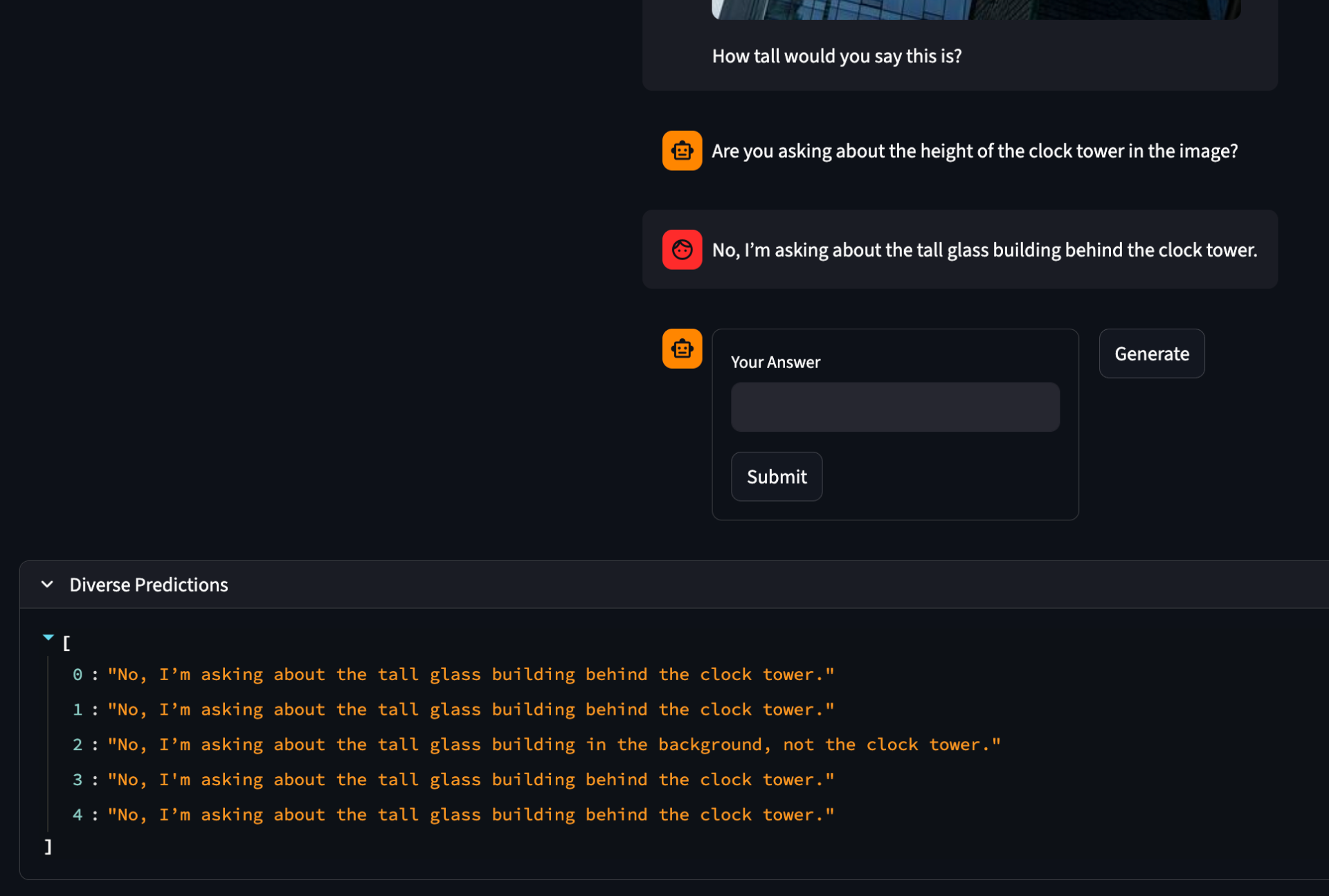
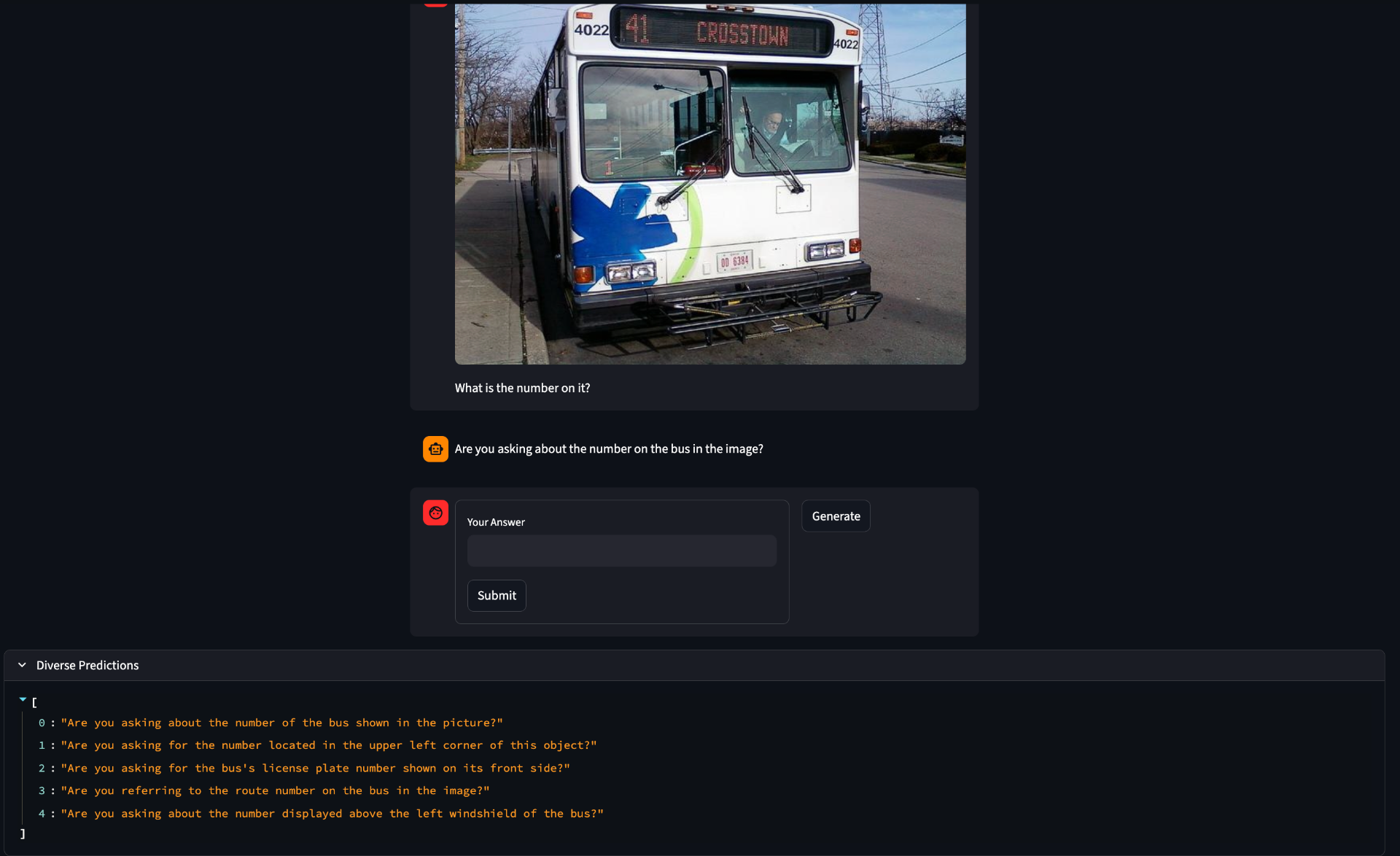
I've gotten diverse sampling somewhat working. I tried out group beam search, but the quality of the outputs was very low. Instead, I just used normal temperature scaling which worked much better.
generated_ids = model.generate(
**inputs,
do_sample=True, # Enable sampling
temperature=1.2, # High temperature to encourage diverse answers
top_p=0.95, # Nucleus sampling
top_k=50, # Limit sample pool to top 50 tokens
num_return_sequences=num_samples, # Generate 5 different samples per prompt
max_new_tokens=self.max_new_tokens
)
Another question is how not to waste compute. Clearly from these responses we can see that often there really is only one output in the diverse set. This happens more often with the answer model than the cq model, but it happens in both. What could be done is to use a sentence embedding model and then enfore some minimum distance to consider two sentences different or a clustering algorithm like DBscan as a preprocessing step with further cutting down into only the most diverse samples.
04/02/2026 3:51 PM
I'm struggling a bit to get the answer model to be vague. It tends to provide much more information than was was asked for in the question.
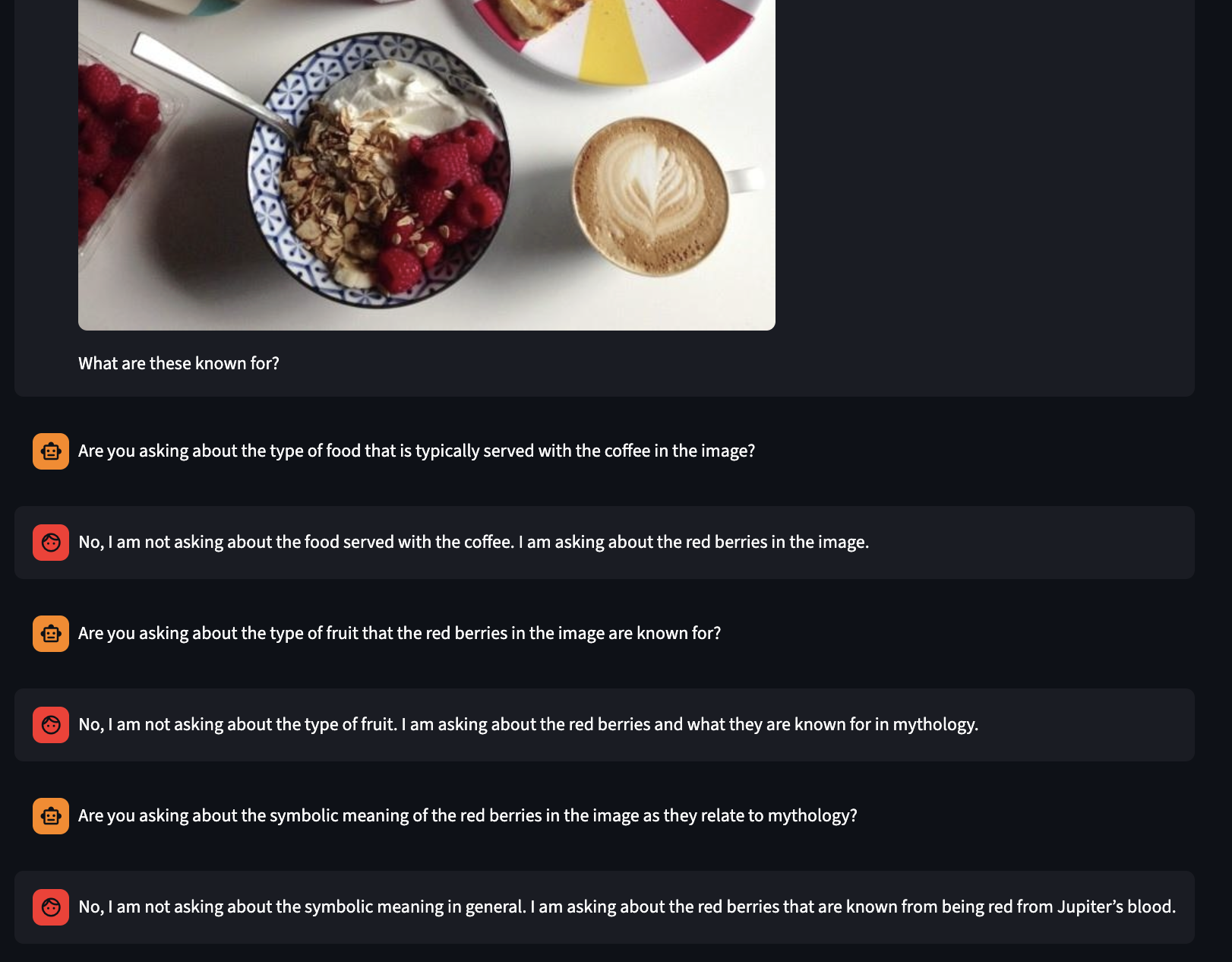
Like here it even seems to try to be vauge, but then gives away the answer after a while of the clarification model floundering

If we look in the diverse answers we can see that some of them remain ambiguous and so some branches of the tree would be useful, but many will just be useless. Perhaps we frame this as a bit of a minimax where we train on the branches that are the deepest which correspond to cases where the answer model is vauge or even incorrect (which I have seen happen). So maybe depth relative to other branches is a proxy for how hazy the answer model is being.
-
[ ] @TODO Implement diverse sampling
-
[ ] @TODO 504 Homework
-
[ ] @TODO Read this article Jason sent https://ai.engin.umich.edu/2023/08/17/eight-lessons-learned-in-two-years-of-ph-d/