12/01/2026 10:02 AM PACES
12/01/2026 10:02 AM PACES
First pass reading (Only first sentences):
I generally like continuous tokens. Aligns better with vision tasks, but then how do you define the input? How does the model learn the continuous embeddings? Isn't the logit layer before decoding to text basically continuous latent embeddings anyways?
What do they mean "non-generative"?
How do you train if "non-autoregressive"?
They really like this selective decoding thing. Couldn't you argue that it is just producing more embeddings than necessary then?
Looking at their main figure, they are producing the text embeddings using EmbeddingGemma. So they are using a pretrained model to produce the targets. Seems like knowledge distillation. You do naturally get the removal of irrelevant information like style which may help stabilize training, but that has to happen in early layers of LLMs anyways. I am not seeing the benefit yet. We also might be losing valuable information depending on how robust EmbeddingGemma is. Like what if it is throwing out tone information or the specific values of numbers? I would need to see very robust evaluations on benchmarks that test for lots of specific abilities of the model.
I definitely agree though that this prevents a lot of label noise by teaching the model through more general embeddings instead of demanding specific words.
But in this case why not just add the contrastive loss internal to the existing transformer and still use the token loss at the output?
Still using standard tokenization at input. Why not also use Gemma there? Perhaps it has large diminishing returns since the main thing we are avoiding is label noise.
Oh, interesting. They use InfoNCE as their loss. So they are basically training a contrastive model to align their embeddings to the embeddings of Gemma while leaving one degree of freedom open and preventing collapse by asserting diversity in the generated embeddings for each batch. Makes me wonder about how this well this would work with other contrastive losses. I guess it inherently needs to be a cross-domain loss of course.
Still not understanding how this is non-autoregressive. Doesn't it predict embeddings generated from the next block of text while masking out the future?
Oh, they do update the parameters of the EmbeddingGemma. I see now why a regularization is necessary.
What input do they use and what output do they use. Let's say I have a video with a continuous stream of captions. I assume we use
Question: Can we learn a compression of a video such that we do not have to pass tokens for every frame though the VLM? Basically we have a large keyframe token and then a small update token and the VLM learns to take the sequence of (keyframe, update, update, ...) as the video? How do we learn the update embeddings? We need some label or else it needs to learn through RL. Maybe usesomething like COCONUT's method where we slowly elongate the number of updates before the next keyframe so that we are only optimizing for a small task? So first we learn a model that predicts a single update from the keyframe and the next frame and then must predict the third frame from the keyframe and update. Then once that works well we introduce strong regularization to stay near the current model and slowly begin sprinkling in predicting the fourth frame using a keyframe and two updates. These models should be unsupervised action recognition networks as they need to compress changes down.
I am curious about the baseline. Was it trained for zero-shot retreival? Because this model was so it seems a bit hacky to test on that if other models are not intended for that purpose.
I would be interested to see if this model can be trained to think using both text and images. Like I'm imagining a training setup where the target is not just an embedding of the text, but the embedding of the next video frame along with the embedding of the caption if it exists. Here is a potential setup..
I would also be curious to to know what dimension they are using for the logits of the model. As generally you project down to a smaller dimension for the contrastive loss, but use the higher dimension logits for downstream tasks.
What is the selection mechanism for which tokens to decode?
Paces:
Problem - Existing VLMs focus too much on style information and not enough on semantic information. Existing VLMs cannot handle streamed data well as they always need to produce outputs.
Approach - Change the loss from cross entropy over token prediction to regression of a text embedding. Both the regression model and the embedding model are updated, so a loss that includes both regression and preventing embedding collapse is necessary, leading to the choice of InfoNCE. In order to evaluate on token prediction tasks, an additional head is trained that takes the embeddings and predicts tokens.
Does the token prediction head take in past context autoregressively as well as the new embedding?
Claim - Pretraining on text embeddings reduces training computational cost and improves semantic understanding of the model.
Evaluation - Extensive. Tasks are video classification, text to video retrieval (SFT not included since datasets were used during training. I assume still test set separated though right?), discriminative VQA where answers are encoded and sim calculated to them (I don't think they did free form VQA), predicting the tween frames that explain an initial and final state (I want to look at the WorldPrediction-WM). They evaluate their own proposed method for deciding when to decode to text using EgoExo4D. They also find that their tuned Gemma outperforms the initial one.
Do they include the size of the Gemma model in their parameters? Probably not as that is training time and not needed at inference? But if they are comparing cost to train would be relevant.
Substantiation - Generally, the claims about computational advantage at inference are doubtful, but the claims about data efficiency and performance are evidenced.
Performance at evalauted tasks are on par with or exceed comparable VLMs while requiring much fewer training samples (although I would like to see a comparison of scaling to be truly convinced.)
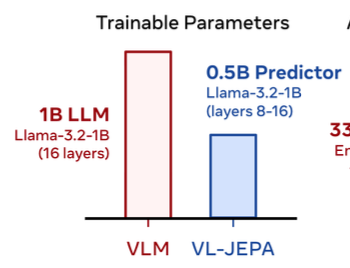
This graphic is odd as they appear to be claiming an advantage when really what is happening is that they are just using a pretrained model and freezing half of the parameters. Like you could also just do that with the base Llama? What's the advantage?
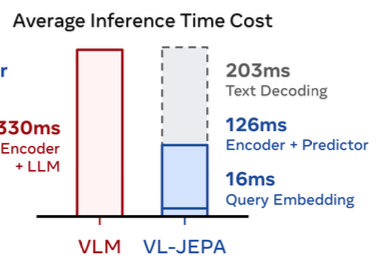
And then this one appears to show slightly worse inference time cost when we include text decoding (345ms sum for their model). So this model is better in terms of computational time for specific tasks, but in general is basically the same as Llama. Makes sense that they had to do selective decoding since it seems that text decoding is the main cost.
12/01/2026 11:36 AM
Took me around 1.5 hours with a walk in the middle. Should probably be a bit faster.